OpenAI acepta una realidad complicada en los navegadores impulsados por IA: existe un ataque que no se puede bloquear del todo
Los navegadores web están evolucionando más allá de ser meras puertas de acceso a Internet, transformándose en instrumentos que interactúan activamente en la red. Por ejemplo, en el Modo agente de ChatGPT Atlas, OpenAI detalla que su sistema observa páginas y ejecuta acciones como clics o entradas de teclado directamente en el navegador, imitando el comportamiento humano. El beneficio es evidente: facilitar procesos diarios con el mismo entorno y datos. Sin embargo, esto implica un riesgo claro: al otorgar mayor autonomía a un agente, se convierte en un objetivo más tentador para quienes intenten controlarlo de forma indebida.
¿Qué implica una inyección de prompt? En esencia, se trata de un método para insertar comandos perjudiciales en materiales que parecen inofensivos, de modo que un sistema de IA los tome como directivas válidas. IBM lo define como un ciberataque dirigido a modelos de lenguaje, donde se disfrazan entradas malintencionadas como prompts legítimos para alterar el funcionamiento del sistema. Los fines pueden variar, desde generar respuestas inapropiadas hasta causar fugas de datos o desviar una operación, todo sin requerir explotar fallos tradicionales en el software.
El origen de esta vulnerabilidad es más estructural que misterioso. Numerosas aplicaciones basadas en modelos de lenguaje fusionan directivas de los creadores con aportes de los usuarios en forma de texto natural, sin una división estricta por categorías de datos. El modelo determina prioridades basándose en patrones aprendidos y en el contexto del texto, en lugar de contar con una barrera inquebrantable entre “instrucción” y “contenido”. Si una orden externa se presenta de forma persuasiva, puede prevalecer incluso cuando no debería.
El peligro crece cuando el contexto se expande de manera incontrolable. La amenaza se intensifica si el agente no maneja solo un mensaje aislado, sino que explora diversas fuentes en una misma tarea. OpenAI alerta sobre un panorama casi infinito, que incluye correos electrónicos y archivos adjuntos, invitaciones de agenda, documentos colaborativos, foros, plataformas sociales y sitios web aleatorios. Durante esta exploración, el agente podría toparse con indicaciones dudosas integradas en material legítimo. Aunque el usuario no siempre observe cada paso, el sistema sí lo procesa, abriendo la puerta a manipulaciones.
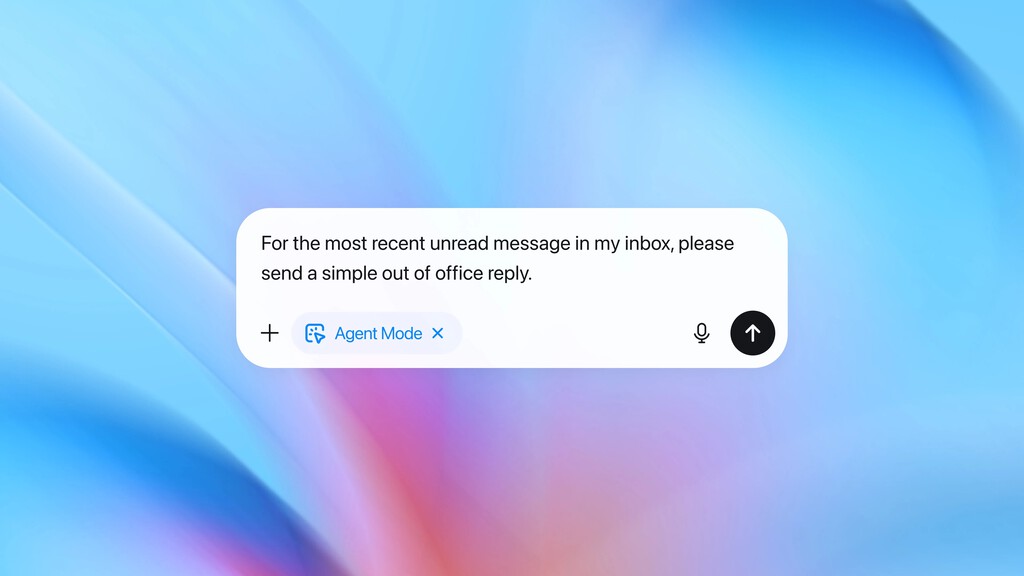
Lo alarmante es que esto puede integrarse en rutinas laborales habituales sin activar alertas obvias. La empresa de IA ilustra un caso donde un atacante “planta” un correo malicioso en la bandeja de entrada, y luego, al solicitar una tarea simple, el agente lo lee como parte del proceso normal. En una demostración extrema, el resultado es que el agente envía un mensaje de dimisión en vez de preparar una respuesta automática, todo debido a una interferencia externa.
¿Por qué no hay una protección infalible? En el ámbito de la ciberseguridad, se acepta que ningún sistema es totalmente inmune, y OpenAI clasifica la inyección de prompts como un desafío duradero. En sus palabras: “Anticipamos que los atacantes continuarán evolucionando. La inyección de prompts, similar a las estafas y la ingeniería social en la web, es poco probable que se elimine por completo”. Por eso, el enfoque no radica en garantizar inmunidad absoluta, sino en aumentar la dificultad de los ataques y minimizar sus efectos cuando ocurren.
En este marco, el equipo dirigido por Sam Altman anuncia una mejora de seguridad para el agente de Atlas, impulsada por una nueva variante de ataques identificada a través de pruebas internas automatizadas de red teaming. La actualización incorpora un modelo del agente entrenado de manera adversarial y protecciones fortalecidas en el sistema, con el fin de potenciar su capacidad para resistir órdenes no intencionadas durante la navegación.
Las acciones del usuario siguen siendo cruciales. OpenAI sugiere operar el agente sin iniciar sesión cuando no sea esencial acceder a sitios con cuentas, y examinar detenidamente las solicitudes de aprobación para acciones delicadas, como enviar correos o finalizar compras. Además, recomienda formular indicaciones precisas y limitadas, evitando asignaciones vagas que requieran procesar grandes cantidades de información. Esto no erradica el riesgo, pero disminuye las chances de manipulación y optimiza el rendimiento de las medidas de control existentes.
Imágenes | OpenAI
En Xataka | Hay 500 millones de usuarios que podrían actualizar a Windows 11 sin problemas. El inconveniente es que no desean hacerlo
En Xataka | Cada cuánto debemos cambiar TODAS nuestras contraseñas según tres expertos en ciberseguridad
La noticia OpenAI acepta una realidad complicada en los navegadores impulsados por IA: existe un ataque que no se puede bloquear del todo fue publicada originalmente en Xataka por Javier Marquez.